
В мире SEO важно понимать систему, которую вы оптимизируете.
Вам нужно знать, как:
- Поисковые системы просматривают и индексируют веб-сайты.
- Функционируют поисковые алгоритмы.
- Поисковые системы рассматривают намерения пользователя как сигнал ранжирования (и к чему они, вероятно, идут с этим).
Еще одна важная область для понимания – это машинное обучение.
Теперь термин "машинное обучение" часто используется в наши дни.
Но как машинное обучение фактически влияет на поиск и SEO?
Эта глава рассмотрит все, что вам нужно знать о том, как поисковые системы используют машинное обучение.
Что такое машинное обучение?

Было бы трудно понять, как поисковые системы используют машинное обучение, не зная, что такое машинное обучение на самом деле.
Давайте начнем с определения (предоставленного Стэнфордским университетом в описании своего курса для Coursera), прежде чем мы перейдем к практическому объяснению:
«Машинное обучение – это наука о том, чтобы заставить компьютеры действовать, не явно программируя их.»
Небольшое отступление, прежде чем мы продолжим...
Машинное обучение не то же самое, что и искусственный интеллект (ИИ), но граница между ними начинает становиться несколько размытой с применениями.
Как указано выше, машинное обучение – это наука о том, чтобы заставить компьютеры приходить к выводам на основе информации, но без явного программирования в том, как выполнить задачу.
С другой стороны, ИИ – это наука создания систем, которые имеют или кажутся обладающими интеллектом, схожим с человеческим, и обрабатывают информацию аналогичным образом.
Думайте об этом различии так:
Машинное обучение – это система, разработанная для решения проблемы. Она работает математически для создания решения.
Решение может быть специально программировано или ручным образом разработано людьми, но без этой необходимости решения приходят намного быстрее.
Хорошим примером было бы отправить машину на просмотр огромного объема данных о размере и местоположении опухолей без программирования того, что она ищет. Машине бы предоставили список известных доброкачественных и злокачественных заключений.
Затем мы бы попросили систему создать прогностическую модель для будущих встреч с опухолями для генерации заранее шансов на то, какими они являются на основе проанализированных данных.
Это чистая математика.
То же самое задание могли бы выполнить несколько сотен математиков, но это заняло бы у них много лет (при условии очень большой базы данных), и, надеюсь, ни один из них не сделает ошибок.
Или это же задание можно было бы выполнить с использованием машинного обучения – гораздо быстрее.
Когда я думаю об искусственном интеллекте, я начинаю думать о системе, которая касается творчества и, следовательно, становится менее предсказуемой.
Искусственный интеллект, нацеленный на ту же задачу, может просто ссылаться на документы по этой теме и выводить заключения из предыдущих исследований.
Или он может добавить новые данные в этот микс.
Или начать работать над новой системой электрического двигателя, откладывая первоначальную задачу.
Возможно, это не отвлечется в Facebook, но вы понимаете, к чему я иду.
Ключевое слово – интеллект.
Хотя искусственный, чтобы соответствовать критериям, он должен быть реальным, таким образом, создавая переменные и неизвестные, аналогичные тем, с которыми мы сталкиваемся, общаясь с другими вокруг нас.
Вернемся к машинному обучению и поисковым системам
В настоящее время то, что поисковые системы (и большинство ученых) стремятся развивать – это машинное обучение.
Google предоставляет бесплатный курс по этой теме, сделал свой фреймворк машинного обучения TensorFlow открытым для общественности и вкладывает большие средства в аппаратное обеспечение для его запуска.
По сути, это будущее, поэтому лучше его понимать.
Хотя невозможно перечислить (или даже знать) все приложения машинного обучения, которые происходят в Googleplex, давайте рассмотрим несколько известных примеров:
RankBrain
Какая статья о машинном обучении в Google была бы полной без упоминания их первой и по-прежнему актуальной реализации алгоритма машинного обучения в поиске?
Это верно, мы говорим о RankBrain.
По сути, система была вооружена только пониманием сущностей (вещь или концепция, которая является единственной, уникальной, четко определенной и различимой) и задачей производить понимание того, как эти сущности связаны в запросе, чтобы лучше понимать запрос и набор известных правильных ответов.
Это крайне упрощенные объяснения как сущностей, так и RankBrain, но они служат нашим целям здесь.
Таким образом, Google предоставил системе некоторые данные (запросы) и, вероятно, набор известных сущностей.
На следующем этапе система, логически, должна была обучиться на основе начального набора сущностей, как распознавать неизвестные сущности, с которыми она сталкивается.
Система была бы бесполезной, если бы не могла понимать новое название фильма, дату и т. д.
Как только система освоила этот процесс и давала удовлетворительные результаты, ее, вероятно, поручили обучить себя тому, как понимать отношения между сущностями и какие данные предполагаются или непосредственно запрашиваются, и искать подходящие результаты в индексе.
Эта система решает множество проблем, с которыми сталкивалась Google.
Необходимость включать ключевые слова вроде "Как заменить экран моего S7" на страницу о замене не должна быть необходимой.
Также необходимо включать "исправить", если уже включено "заменить", так как в этом контексте они в общем случае подразумевают одно и то же.
RankBrain использует машинное обучение для:
- Постоянного изучения взаимосвязей сущностей и их отношений.
- Понимания, когда слова являются синонимами, а когда нет (в данном случае "заменить" и "исправить" могут быть синонимами, но не будут таковыми, если я бы запросил "как починить свой автомобиль").
- Давать указания другим частям алгоритма создавать правильные результаты на странице результатов поиска.
В своей первой итерации RankBrain был протестирован на запросах, с которыми Google раньше не сталкивался. Это вполне логично и отличный тест.
Если RankBrain может улучшить результаты для запросов, которые, вероятно, не были оптимизированы и включают в себя смесь старых и новых сущностей и услуг, ф так же группу пользователей, изначально получавших неудовлетворительные результаты, то его следует развернуть глобально.
И это произошло в 2016 году.
Давайте посмотрим на два результата, на которые я ссылался выше. (Следует отметить, что я сначала написал статью и только потом решил сделать скриншот – это просто так работает, попробуйте сами ... это работает в почти всех случаях, когда различная формулировка подразумевает одно и то же):
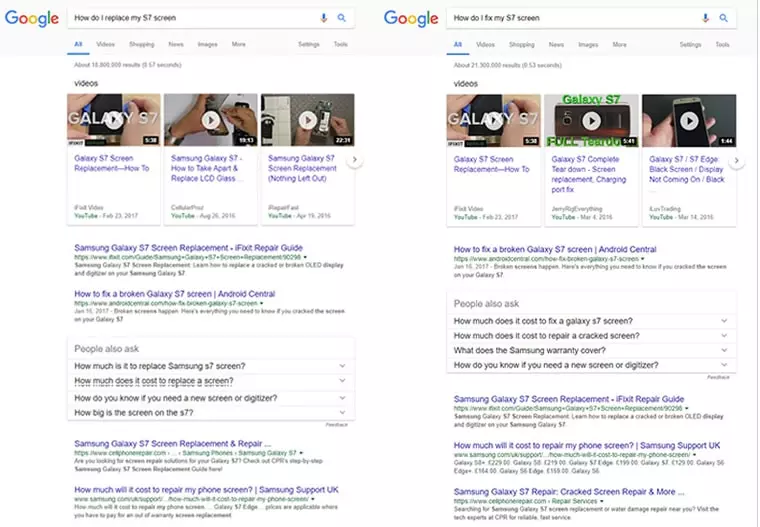
Некоторые очень тонкие различия в рейтингах с переключением мест между первым и вторым сайтом, но в основе это тот же результат.
Теперь давайте посмотрим на мой пример из автомобильной сферы:
Машинное обучение помогает Google не только понимать, где есть сходство в запросах. Так же мы видим, как оно определяет, что если мне нужно починить свой автомобиль, мне, возможно, понадобится механик (правильный выбор Google). Для замены я могу обращаться к деталям или нуждаться в документации для полной замены.
Мы также видим, где машинному обучению еще не удалось полностью разобраться.
Когда я спрашиваю, как заменить свой автомобиль, я, вероятно, имею в виду весь автомобиль, или я бы указал часть, которую я хочу.
Но оно учится ... оно все еще в своем начале.
К тому же я канадец, поэтому DMV не совсем подходит.
Итак, здесь мы видели пример применения машинного обучения для определения смысла запроса, макета страницы результатов поиска и возможных необходимых шагов для выполнения моего намерения.
Не все это RankBrain, но все это машинное обучение.
Спам
Если вы используете Gmail или практически любую другую электронную почту, вы также видите машинное обучение в действии.
По словам Google, теперь они блокируют 99,9% всех спам-писем и фишинговых писем с ложноположительной ставкой всего 0,05%.
Они делают это с использованием той же основной техники – предоставьте машинному обучению некоторые данные и позвольте ему работать.
Если бы кто-то руками программировал все перестановки, которые дали бы успех в 99,9% фильтрации спама и корректировались бы на лету для новых техник, это была бы трудная задача, если бы вообще возможная.
Когда они делали это вручную, они достигли успеха на уровне 97% с ложноположительным результатом 1% (то есть 1% ваших реальных сообщений попадали в папку спама – неприемлемо, если это было важно).
Ввод машинного обучения – настройте его с сообщениями о спаме, которые вы можете положительно подтвердить, позвольте ему создать модель на основе сходств этих сообщений, введите новые сообщения и предоставьте ему вознаграждение за успешное выбор спам-сообщений самостоятельно, и со временем (и не так много времени) он выучит гораздо больше сигналов и будет реагировать гораздо быстрее, чем человек когда-либо смог бы.
Введение в машинное обучение – настройте его на все спам-сообщения, которые вы можете положительно подтвердить, позвольте ему построить модель на основе сходства, введите новые сообщения и вознаградите его за успешный выбор спама самостоятельно, и со временем (и не так много времени) он узнает гораздо больше сигналов и реагирует гораздо быстрее, чем человек когда-либо смог бы.
Настройте его на отслеживание взаимодействий пользователя с новыми структурами электронной почты, и когда он узнает, что используется новая техника спама, добавьте ее в общую картину и фильтруйте не только эти электронные письма, но и письма, использующие подобные техники, в папку спам.
Так как работает машинное обучение?
Эта статья обещала предоставить объяснение машинного обучения, а не просто перечень примеров. Однако примеры были необходимы для иллюстрации довольно простой модели.
Давайте не путаем это с простотой создания, просто простотой в понимании.
Обычная модель машинного обучения следует следующей последовательности:
- Предоставьте системе набор известных данных. То есть набор данных с большим массивом возможных переменных, связанных с известным положительным или отрицательным результатом. Это используется для обучения системы и дает ей отправную точку. По сути, теперь она понимает, как распознавать и взвешивать факторы на основе прошлых данных для достижения положительного результата.
- Настройте вознаграждение за успех. Как только система привыкнет к начальным данным, ей затем подают новые данные, но без известного положительного или отрицательного результата. Система не знает отношений новой сущности или является ли электронное письмо спамом или нет. Когда она правильно выбирает, ей предоставляется вознаграждение, хотя, очевидно, не шоколадка. Примером может служить предоставление системе значения вознаграждения с целью достижения максимально возможного числа. Каждый раз, когда она выбирает правильный ответ, этот балл добавляется.
- Оставь в покое. Как только метрики успеха станут достаточно высоки для превзойдения существующих систем или достижения другого порога, систему машинного обучения можно интегрировать в алгоритм в целом.
Эта модель называется обучением с учителем, и если я правильно догадываюсь, это модель, используемая в большинстве реализаций алгоритмов Google.
Другая модель машинного обучения – это наблюдаемая модель.
Чтобы воспользоваться примером, приведенным в отличном курсе на Coursera по машинному обучению, это модель, используемая для группировки похожих историй в Google News, и можно предположить, что она используется в других местах, таких как выявление и группировка изображений, содержащих тех же или похожих людей в Google Images.
В этой модели системе не говорят, что искать, а просто просят сгруппировать сущности (изображение, статью и т. д.) в группы по схожим признакам (содержащиеся в них сущности, ключевые слова, отношения, авторы и т. д.)
Почему это важно?
Понимание того, что такое машинное обучение, станет ключевым, если вы стремитесь понять, почему и как формируются результаты поиска и почему страницы ранжируются там, где они находятся.
Одно дело – понимать алгоритмический фактор, что, безусловно, важно, но понимание системы, в которой эти факторы взвешены, также имеет равное, если не большее значение.
Например, если бы я работал в компании, которая продает автомобили, я бы уделил внимание отсутствию полезной, актуальной информации в результатах SERP для запроса, проиллюстрированного выше.
Результат явно неудачен. Узнайте, какой контент был бы успешен, и создайте его.
Обратите внимание на типы контента, которые Google считает возможным удовлетворить намерение пользователя (пост, изображение, новости, видео, покупки, рекомендованное фрагментирование и т. д.) и работайте над его предоставлением.
Мне нравится думать о машинном обучении и его эволюции как о том, что за каждым пользователем находится инженер Google, настраивающий то, что они видят и как они это видят, прежде чем это отправится на их устройство.
Но лучше – этот инженер подключен, как Борг, ко всем другим инженерам, изучая глобальные правила.
Но мы подробнее рассмотрим это в следующей главе о намерениях пользователей.