
автор: Dave Davies
Основная цель поисковой системы – помочь пользователям выполнять задачи (и, конечно, продавать рекламу).
Иногда эта задача может включать в себя получение сложной информации. Иногда пользователю просто нужен один ответ на вопрос.
В этой главе вы узнаете, как поисковые системы определяют, к какой категории относится запрос, и как они затем определяют ответ.
Как поисковые системы классифицируют типы запросов
На этот вопрос можно написать целые статьи или, вероятно, книги. Но мы попытаемся кратко изложить это в нескольких сотнях слов.
Стоит сказать, что RankBrain практически не играет здесь никакой роли. Так что происходит на самом деле? По сути, первый шаг в этом процессе – понять, какая информация запрашивается.
То есть классификация запроса как вопроса: кто, что, где, когда, почему и как.
Эта классификация может происходить независимо от того, содержатся ли эти конкретные слова в запросе, как показано на:
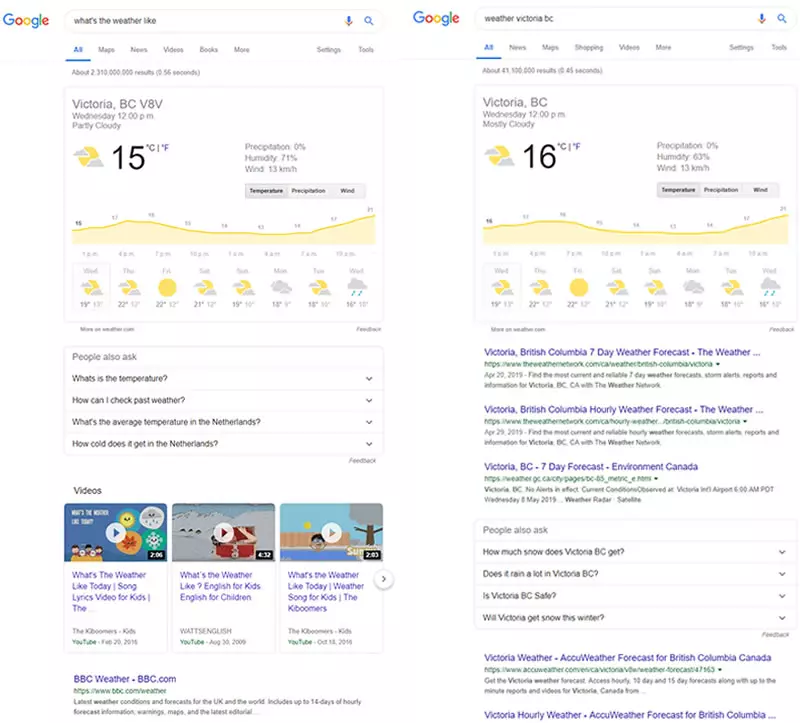
Итак, что мы видим здесь, происходит две вещи:
- Google определил, что пользователь ищет ответ на вопрос, как, вероятно, основное намерение.
- Google определил, что если это не является основным намерением пользователя, то вторичные намерения, вероятно, разнообразные.
Возможно, вас интересует, как поисковые системы могут определить, что пользователь задает вопрос во втором примере выше. Ведь это не встроено в запрос.
И в первом примере, каким образом они заключают, что пользователь ищет информацию о погоде в своем местоположении, а не просто в общем.
Существует несколько систем, которые соединяются и предоставляют данные для создания этой среды. В основе этого лежит следующее:
Канонические запросы
Мы обычно думаем о запросе как о единичном запросе с единичным ответом. На самом деле это не так.
Когда выполняется запрос, если нет известного правильного намерения или когда поисковая система может захотеть проверить свои предположения, у нее есть метод создания канонических запросов.
Google изложил этот процесс в патенте, полученном в 2016 году и названом "Оценка семантических интерпретаций поискового запроса". В краткосрочной перспективе проблема резюмируется на следующей картинке:
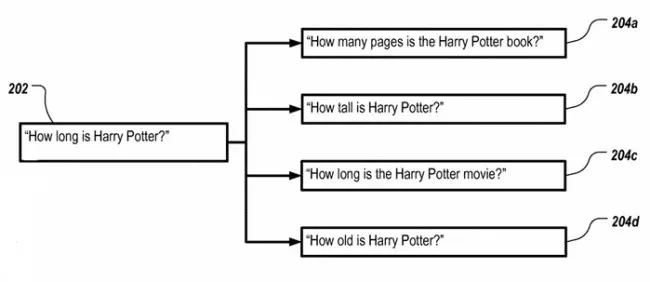
Один запрос с несколькими возможными значениями.
В патенте они изложили процесс, при котором все возможные интерпретации могут использоваться для получения результата. Они бы создали набор результатов для всех пяти запросов.
Они сравнивали результаты запросов 204a, 204b, 204c и 204d с результатами от 202. Тот, который из серии 204 больше всего соответствует результату от 202, считается наиболее вероятным намерением.
Судя по текущим результатам, 204c победил:
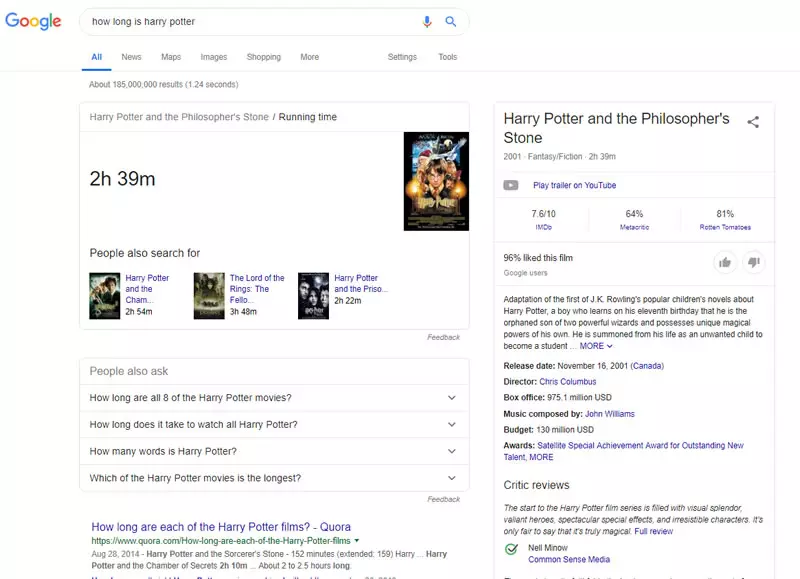
Что потребовало два раунда этого процесса.
Первый, чтобы выбрать фильм, второй, чтобы выбрать, какой фильм.
И чем меньше людей переходит по результатам поиска с этой страницы, тем успешнее считается результат, что описано в патенте в утверждении:
"Используя результаты поиска для оценки различных семантических интерпретаций, учитываются другие источники данных, такие как данные о кликах, данные, специфичные для пользователя, и другие, которые используются при формировании результатов поиска, без необходимости дополнительного анализа".
Относительно контекста патента это не означает, что CTR является прямым метрическим показателем. Фактически это утверждение ближе к тому, что Джон Мюллер имел в виду, когда отвечал на вопрос о том, использует ли Google метрики пользователей:
"... это то, что мы рассматриваем для миллионов различных запросов и миллионов различных страниц и в общем видим, идет ли этот алгоритм в правильном направлении или идет ли этот алгоритм в правильном направлении".
По сути, они не используют его для оценки только успеха одного результата, они используют его для оценки успеха всей SERP (включая макет) в целом.
Нейронное сопоставление
Google использует нейронное сопоставление для определения синонимов.
По сути, нейронное сопоставление – это процесс, управляемый искусственным интеллектом, который позволяет поисковикам понимать синонимы на очень высоком уровне.
Чтобы использовать их пример, это позволяет Google формировать результаты, например:
.webp)
Вы видите, что запрос касается ответа на вопрос о том, почему мой телевизор выглядит странно, который система распознала как относящийся к "эффекту мыла".
Ранжированная страница не содержит слова "странный". Так что с ключевой плотностью не всегда все просто.
Их системы искусственного интеллекта ищут синонимы на очень сложном уровне, чтобы понять, какая информация может решить намерение, даже когда это не запрашивается явно.
Ситуационные сходства
Есть различные примеры и области, где в игру вступает ситуативный контекст, но в своей основе нам нужно думать о том, как намерение запроса изменяется в зависимости от ситуационных условий.
Мы упомянули выше патент о системах, которые создают канонические запросы. Включен в этот патент – идея создания шаблона.
Шаблон, который можно использовать для других подобных запросов, чтобы ускорить процесс.
Так что, если были затрачены ресурсы на определение того, что, когда кто-то вводит одно слово, которое обычно имеет широкий контекст, вероятно, он хочет определение. Это можно применить более универсально, производя результаты, например:
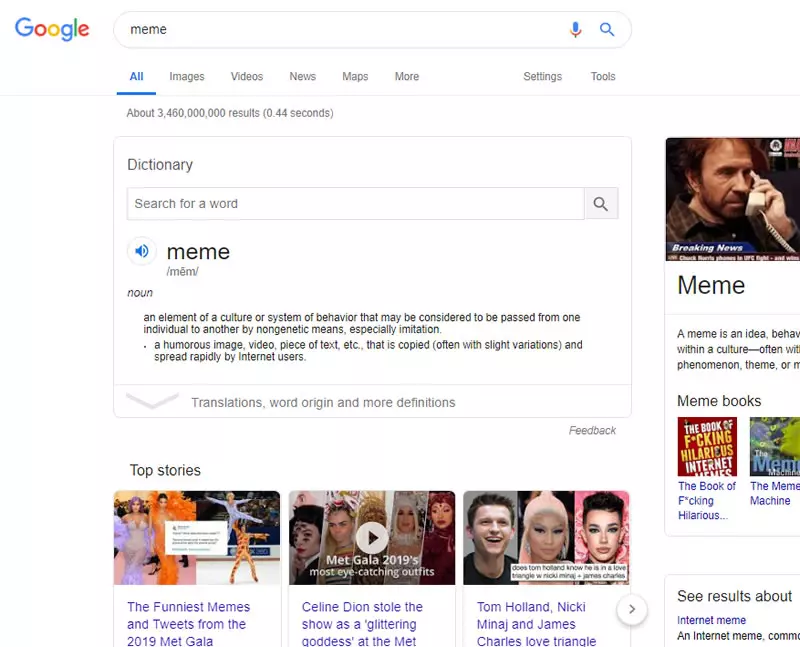
И оттуда начинайте искать шаблоны исключений, таких как еда.
И говоря о еде, это служит отличным примером, поддерживающим мое убеждение (и логику, как мне кажется), что также очень вероятно, что поисковые системы используют объемы поиска.
Если для термина "пицца" люди ищут рестораны чаще, чем рецепты, то разумно, что они используют это как метрику. Они решают, что если продукт питания не следует этому шаблону, то шаблон не применим.
Начальные наборы
Развивая идею шаблонов, я считаю, что используются начальные наборы данных. Сценарии, где системы, запрограммированные инженерами, обучаются на реальном понимании того, чего хотят люди, и создают шаблоны.
На самом деле я не читал ничего о начальных наборах в этом контексте, но это имеет смысл и, безусловно, существует.
Прошлые взаимодействия
Поисковые системы будут тестировать, правильно ли они понимают намерение, размещая результат в подходящем макете и наблюдая за действиями пользователей.
В нашем контексте выше, если возможным намерением запроса "какая погода" является то, что я ищу ответ на вопрос, они проверят это предположение.
Как кажется, в большом масштабе это ответ, который люди хотят.
Итак, что это имеет отношение к ответам на вопросы?
Отличный вопрос.
Чтобы понять, как Google отвечает на вопросы, нам нужно сначала понять, как они могут собирать данные, чтобы определить, является ли запрос вопросом.
Конечно, легко, когда это запрос кто, что, где, когда, почему или как.
Но мы должны подумать о том, как они знают, что запрос типа "погода" или "мем" – это запрос на получение конкретной информации.
Как только это установлено с использованием взаимосвязи вышеописанных методов в сочетании (и, конечно, еще нескольких, которые я, возможно, упустил), остается только найти ответ.
Так что пользователь ввел одно слово, и поисковая система перепрыгнула через множество преград, чтобы установить, что, вероятно, это запрос на получение конкретного ответа. Теперь им остается определить, что это за ответ.