
автор: Stoney G deGeyter
На арене SEO-архитектуры веб-сайта нет сомнения в том, что устранение дублированного контента может быть одной из самых трудных проблем.
Слишком много систем управления контентом и некачественных разработчиков создают сайты, которые отлично отображают контент, но мало заботятся о том, как этот контент функционирует с точки зрения дружелюбности поисковых систем.
И это часто оставляет для SEO проблемы с дублированным контентом, с которыми приходится бороться.
Существуют два вида дублированного контента, и оба могут стать проблемой:
- Внутреннее дублирование – это когда один и тот же контент дублируется на двух или более уникальных URL-адресах вашего сайта. Обычно это что-то, что может контролироваться администратором сайта и командой веб-разработки.
- Внешнее дублирование – это когда два или более веб-сайта публикуют точно такие же фрагменты контента. Обычно это нечто, что нельзя контролировать напрямую, но зависит от взаимодействия с третьими сторонами и владельцами нарушающих правила веб-сайтов.
Почему дублированный контент проблема?
Лучший способ объяснить, почему дублированный контент плох – сначала рассказать вам, почему уникальный контент хорош.
Уникальный контент – это один из лучших способов выделиться среди других веб-сайтов. Когда контент на вашем сайте принадлежит только вам, вы выделяетесь. У вас есть то, чего у других нет.
С другой стороны, когда вы используете одинаковый контент для описания своих продуктов или услуг или контент перепубликуется на других сайтах, вы теряете преимущество уникальности.
Или, в случае внутреннего дублирования контента, отдельные страницы теряют преимущество уникальности.
Посмотрите на иллюстрацию ниже.
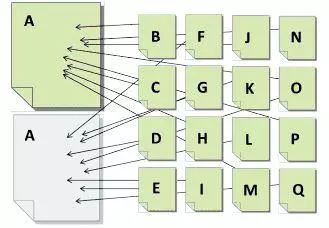
Если A представляет собой контент, который дублируется на двух страницах, а B-Q представляют собой страницы, ссылки на этот контент, дублирование вызывает разделение передаваемой ценности ссылки.
Теперь представьте, что страницы B-Q все связаны только с одной страницей A. Вместо разделения значения, предоставляемого каждой ссылкой, все значение будет передано на один URL, что увеличивает шансы этого контента на ранжирование в поиске.
Иногда, независимо от того, является ли контент дублированным внутри сайта или за его пределами, дублированный контент конкурирует сам с собой. Каждая версия может привлекать внимание и ссылки, но ни одна не получит полную ценность, которую она получила бы, если была бы единственной и уникальной версией.
Однако когда ценный и уникальный контент можно найти только на одном URL где-либо в Интернете, этот URL имеет лучший шанс быть обнаруженным, основываясь на том, что он является единственным сборщиком сигналов авторитетности для этого контента.
Теперь, понимая это, давайте рассмотрим проблемы и решения для дублированного контента.
Дублированный контент за пределами сайта
Внешнее дублирование контента имеет три основных источника:
- Контент от сторонних источников, который вы опубликовали на своем собственном сайте. Обычно это представляет собой общие описания продуктов, предоставленные производителем.
- Ваш контент, который был опубликован на сторонних сайтах с вашего разрешения. Обычно это происходит в форме распространения статей или, возможно, обратного распределения статей.
- Контент, который кто-то украл с вашего сайта и опубликовал без вашего разрешения. Здесь копирайтеры и воришки контента становятся неудобством.
Давайте рассмотрим каждый из указанных выше вариантов.
Копирайтеры и воришки контента
Копирайтеры контента – одни из крупнейших нарушителей создания дублированного контента. Спамеры и другие злоумышленники создают инструменты, которые захватывают контент с других веб-сайтов и затем публикуют его на своем собственном.
В большинстве случаев эти сайты пытаются использовать ваш контент для привлечения трафика на свой сайт, чтобы люди нажимали на их рекламу. (Да, я смотрю на тебя, Google!)
К сожалению, с этим не так уж многое можно сделать, кроме как подать жалобу о нарушении авторских прав в Google в надежде, что его удалят из индекса поиска. Хотя в некоторых случаях подача этих отчетов может стать полноценной работой.
Другой способ борьбы с этим контентом – проигнорировать его, надеясь, что Google может отличить качественный сайт (ваш) от сайта, на котором находится скопированный контент. Это не всегда эффективно, поскольку я видел, как скопированный контент ранжируется выше, чем исходный источник.
То, что вы можете сделать для борьбы с эффектами скопированного контента, это использовать абсолютные ссылки (полный URL) внутри контента для любых ссылок, ведущих обратно на ваш сайт. Те, кто крадет контент, как правило, не занимаются его очисткой, так что, по крайней мере, посетители могут следовать по этим ссылкам обратно к вам.
Вы также можете попробовать добавить тег канонического URL обратно на исходную страницу (хорошая практика в любом случае). Если воришки используют этот код, тег канонического URL хотя бы предоставит сигнал Google о том, что вы являетесь автором.
Распределение статей
Несколько лет назад казалось, что каждый SEOшник публиковал свой контент в блогах и электронных журналах в качестве тактики построения ссылок. Когда Google начал бороться с качеством контента и схемами ссылок, публикация ушла на второй план.
Но с правильным фокусом это может быть надежной маркетинговой стратегией. Заметьте, я сказал "маркетинг" вместо "SEO".
В большинстве случаев, когда вы публикуете контент на других веб-сайтах, они хотят уникальные права на этот контент.
Почему? Потому что они не хотят, чтобы множественные версии этого контента в Интернете обесценивали то, что предлагает издатель.
Но по мере того как Google становится лучше в назначении прав на контент (лучше, но не идеалом), многие издатели разрешают повторное использование контента также на личных сайтах автора.
Создает ли это проблему с дублированным контентом? В некотором смысле, да, потому что существуют две версии контента, каждая из которых потенциально создает ссылки.
Но в конце концов, если количество дублированных версий ограничено и контролируется, то и воздействие будет ограниченным. Фактически, основной недостаток касается автора, а не вторичного издателя.
Общие описания продуктов
Некоторые из наиболее распространенных форм дублированного контента исходят от описаний продуктов, которые повторно используют каждый (и почти каждый) продавец.
Многие интернет-ретейлеры продают точно те же продукты, что и тысячи других магазинов. В большинстве случаев описания продуктов предоставляются производителем, который затем загружается в базу данных каждого сайта и представляется на их страницах продуктов.
Хотя макет страниц будет отличаться, основная часть контента страницы продукта (описания продуктов) будет идентичной.
Теперь умножьте это на миллионы различных продуктов и сотни тысяч веб-сайтов, продающих эти продукты, и вы получите много контента, мягко говоря, неуникального.
Как поисковый движок отличает один от другого при выполнении поиска?
С точки зрения чистого анализа контента он этого не делает. Это означает, что поисковый движок должен рассматривать другие сигналы, чтобы решить, какой из них следует ранжировать.
Одним из таких сигналов являются ссылки. Получите больше ссылок, и вы можете победить в соревновании за банальное содержание.
Но если у вас серьезный конкурент, вам, возможно, придется вести долгую борьбу, прежде чем вы сможете догнать их в разделе построения ссылок. Что возвращает вас к поиску другого конкурентного преимущества.
Лучший способ достичь этого – приложить дополнительные усилия для написания уникальных описаний для каждого продукта. В зависимости от количества товаров, это может стать довольно сложным заданием, но в конце концов это будет стоить этого.
Посмотрите на иллюстрацию ниже. Если все серые страницы представляют собой один и тот же продукт с одинаковыми описаниями продуктов, желтый цвет представляет собой тот же продукт с уникальным описанием.
Если бы вы были Google, какой из них вы бы предпочли ранжировать выше?

Любая страница с уникальным контентом автоматически будет иметь встроенное преимущество перед аналогичным, но дублированным контентом. Это может быть или не быть достаточным для превзойдения ваших конкурентов, но это определенно базовый критерий для выделения не только в глазах Google, но и ваших клиентов.
Дублированный контент на сайте
Технически Google обрабатывает весь дублированный контент одинаково, поэтому дублированный контент на сайте фактически не отличается от внешнего дублированного контента.
Однако внутренний дублированный контент менее проще прощения, потому что это один из видов дублирования, который вы можете контролировать. Это как стрелять себе в ногу в сфере SEO.
Внутренний дублированный контент обычно проистекает из плохой архитектуры сайта. Или, скорее всего, из-за плохой разработки веб-сайта!
Крепкая архитектура сайта — это основа крепкого веб-сайта.
Когда разработчики не следуют лучшим практикам, ориентированным на поиск, у вас может возникнуть проблема с потерей ценных возможностей ранжирования вашего контента из-за этой самоконкуренции.
Есть те, кто возражает против необходимости хорошей архитектуры, ссылаясь на пропаганду Google о том, что Google может "разобраться". Проблема в том, что это зависит от того, что Google разберется.
Да, Google может определить, что некоторый дублированный контент должен считаться одним и тем же, и алгоритмы могут учитывать это при анализе вашего сайта, но это не гарантирует, что это произойдет.
Или другими словами, просто потому, что вы знаете умного человека, это не обязательно означает, что он сможет защитить вас от вашей собственной глупости! Если вы полагаетесь на Google, и Google терпит неудачу, вы в засаде.
Теперь давайте подробнее рассмотрим некоторые общие проблемы и решения внутреннего дублированного контента.
Проблема: Дублирование категорий продуктов
Слишком много сайтов электронной коммерции страдают от этого вида дублирования. Это часто вызвано системами управления контентом, позволяющими организовывать продукты по категориям, где один и тот же продукт может быть помечен в нескольких категориях.
В самом этом нет ничего плохого (и это может быть отлично для посетителя), однако при этом система генерирует уникальный URL для каждой категории, в которой появляется один и тот же продукт.
Допустим, вы находитесь на сайте по ремонту дома и ищете книгу по укладке напольных покрытий в ванной комнате. Вы можете найти нужную книгу, следуя любому из этих путей навигации:
- Дом > напольные покрытия > ванная комната > книги
- Дом > ванная комната > книги > напольные покрытия
- Дом > книги > напольные покрытия > ванная комната
Каждый из этих вариантов – это приемлемый путь навигации, но проблема возникает, когда для каждого пути генерируется уникальный URL:
- https://www.myfakesite.com/flooring/bathroom/books/fake-book-by-fake-author
- https://www.myfakesite.com/bathroom/books/flooring/fake-book-by-fake-author
- https://www.myfakesite.com/books/flooring/bathroom/fake-book-by-fake-author
Я видел, как такие сайты создают до десяти URL для каждого отдельного продукта, превращая сайт из 5 тысяч продуктов в сайт с 45 тысячами дублированных страниц. Это проблема.
Если бы наш примерный продукт выше генерировал десять ссылок, эти ссылки распределились бы тремя способами.
Тогда как, если бы страница конкурента для того же продукта получила те же десять ссылок, но только к одному URL, какой URL, вероятно, будет лучше ранжироваться в поиске?
Конкурентский!
И не только это, но поисковые системы ограничивают свою пропускную способность сканирования, чтобы они могли тратить ее на индексацию уникального и ценного контента.
Когда на вашем сайте столько дублированных страниц, есть большая вероятность того, что движок перестанет сканировать, даже не получив долю вашего уникального контента в индекс.
Это означает, что сотни ценных страниц не будут доступны в результатах поиска, и те, которые индексируются, являются дубликатами, конкурирующими друг с другом.
Решение: Главные URL-категоризации
Одним из способов решения этой проблемы является пометка продуктов только одной категорией, а не несколькими. Это решает проблему дублирования, но не обязательно является лучшим решением для покупателей, поскольку устраняет другие варианты навигации для поиска нужных им продуктов. Так что этот вариант можно отбросить.
Другой вариант – полностью убрать любую типа категоризации из URL. Таким образом, несмотря на путь навигации, использованный для поиска продукта, URL продукта сам по себе всегда одинаков, и может выглядеть примерно так:
https://www.myfakesite.com/products/fake-book-by-fake-author
Это решает проблему дублирования, не меняя способ, которым посетитель может переходить к продуктам. Однако недостаток этого метода заключается в том, что вы теряете ключевые слова категорий в URL. Хотя это приносит небольшую пользу в общем SEO, каждый маленький шаг может помочь.
Если вы хотите поднять ваше решение на следующий уровень, получив максимальную оптимизацию при сохранении удобства использования, создайте опцию, позволяющую каждому продукту быть привязанным к "главной" категории, в дополнение к другим.
Когда играет главная категория, продукт может продолжать находиться по нескольким путям навигации, но страница продукта доступна по одному URL, который использует главную категорию.
Такой URL может выглядеть примерно так:
- https://www.myfakesite.com/flooring/fake-book-by-fake-author или
- https://www.myfakesite.com/bathroom/fake-book-by-fake-author или
- https://www.myfakesite.com/books/fake-book-by-fake-author
Это последнее решение в целом является наилучшим, хотя требует некоторых дополнительных программных средств. Однако есть еще одно относительно легкое "решение", которое можно реализовать, но я рассматриваю его только как временное решение, пока не будет реализовано настоящее решение.
Временное решение: Канонические теги
Поскольку опция с главной категоризацией не всегда доступна в стандартных CMS или решениях электронной коммерции, существует альтернативный вариант, который "поможет" решить проблему дублированного контента.
Это включает в себя предотвращение индексации поисковиками всех неканонических URL. Хотя это может уберечь дублированные страницы от индексации поиска, это не решает проблему разделения авторитета страницы. Любая ценность ссылки, отправленной на неканонический URL, будет утрачена.
Лучшим временным решением является использование канонических тегов. Это похоже на выбор главной категории, но обычно требует минимального или нулевого программирования.
Просто добавьте поле для каждого продукта, позволяющее назначить канонический URL, что, по сути, означает "URL, который вы хотите видеть в поиске".
Тег канонического вида:
<link rel="canonical" href="https://www.myfakesite.com/books/fake-book-by-fake-author" />
Несмотря на то, на какой странице находится посетитель, за кулисами тега канонического вида на каждом дублированном URL будет указан единый URL.
В теории это говорит поисковым системам не индексировать неканонические URL и присваивать все остальные метрики ценности к канонической версии.
Это работает большую часть времени, но на практике поисковые системы используют тег канонического вида как "сигнал". Затем они решают применять или игнорировать его по своему усмотрению.
Я всегда рекомендую использовать тег канонического вида, но потому что он ненадежен, рассматривайте его как заплатку, пока не будет реализовано более официальное решение.
Проблема: Избыточное дублирование URL
Одна из основных проблем архитектуры веб-сайта связана с тем, как страницы доступны в браузере.
По умолчанию почти каждую страницу вашего сайта можно получить, используя слегка разные URL-адреса. Если не предпринимать мер, каждый URL ведет к точно такой же странице с точно таким же содержанием.
Рассмотрим только домашнюю страницу: ее можно получить через четыре разных URL:
http://site.comhttp://www.site.comhttps://site.comhttps://www.site.com
А при работе с внутренними страницами вы можете получить дополнительную версию каждого URL, добавив косую черту в конце:
http://site.com/pagehttp://site.com/page/http://www.site.com/pagehttp://www.site.com/page/
И так далее.
Таким образом, у каждой страницы может быть до восьми альтернативных URL. Конечно же, Google должен знать, что все эти URL следует рассматривать как единый, но какой из них?
Решение: 301 Редиректы и Согласованность Внутренних Ссылок
Помимо канонического тега, о котором я упоминал выше, решение здесь заключается в том, чтобы убедиться, что все альтернативные версии URL направляются на канонический URL.
Имейте в виду, что это не только проблема домашней страницы. Та же проблема применима ко всем URL вашего сайта. Поэтому редиректы должны быть установлены глобально.
Убедитесь, что каждый редирект указывает на каноническую версию. Например, если канонический URL – https://www.site.com, каждый редирект должен вести туда. Многие делают ошибку, добавляя дополнительные редиректы, которые могут выглядеть примерно так:
Site.com > https://site.com > https://www.site.comSite.com > www.site.com > https://www.site.com
Вместо этого редиректы должны выглядеть так:
http://site.com > https://www.site.com/http://www.site.com > https://www.site.com/https://site.com > https://www.site.com/https://www.site.com > https://www.site.com/http://site.com/ > https://www.site.com/http://www.site.com/ > https://www.site.com/https://site.com/ > https://www.site.com/
Уменьшив количество редиректов, вы ускоряете загрузку страницы, снижаете использование пропускной способности сервера и уменьшаете возможность ошибок.
Наконец, вам нужно убедиться, что все внутренние ссылки на сайте также ведут к канонической версии. Хотя редирект должен решить проблему дублирования, редиректы могут сбоить, если что-то идет не так на стороне сервера или в процессе реализации. Если это произойдет, даже временно, наличие внутренних ссылок только на канонические страницы может помочь предотвратить внезапное появление проблем с дублированием контента.
Проблема: Параметры URL и Строки Запросов
Долгие годы использование идентификаторов сеансов создавало серьезные проблемы с дублированием контента для специалистов по SEO. Однако современные технологии сделали идентификаторы сеансов практически устаревшими, но возникла другая проблема, которая также плоха, если не хуже: параметры URL.
Параметры используются для получения свежего контента с сервера, обычно на основе одного или нескольких фильтров или выбранных параметров. Два приведенных ниже примера показывают альтернативные URL для одного и того же URL:
site.com/shirts/.
Первый показывает рубашки с фильтром по цвету, размеру и стилю, второй URL показывает рубашки, отсортированные по цене, а затем определенному количеству товаров на странице,
Site.com/shirts/?color=red&size=small&style=long_sleeveSite.com/shirts/?sort=price&display=12
Исходя из этих фильтров, существует три приемлемых URL, которые могут обнаружить поисковые системы. Но порядок этих параметров может изменяться в зависимости от того, в каком порядке они были выбраны, что означает, что у вас может быть еще несколько доступных URL, подобных этим:
Site.com/shirts/?size=small&color=red&style=long_sleeveSite.com/shirts/?size=small&style=long_sleeve&color=redSite.com/shirts/?display=12&sort=price
И так далее:
Site.com/shirts/?size=small&color=red&style=long_sleeve&display=12&sort=priceSite.com/shirts/?display=12&size=small&color=red&sort=priceSite.com/shirts/?size=small&display=12&sort=price&color=red&style=long_sleeve
И так далее.
Вы видите, что это может создать множество URL, большинство из которых не будут извлекать уникальный контент.
Из перечисленных параметров, только стиль, возможно, стоит использовать для создания продажного контента. Все остальные – не настолько важны.
Решение: Параметры для фильтров, не для законных страниц-назначений
Стратегическое планирование навигации и структуры URL критично для предотвращения проблем с дублированием контента.
Часть этого процесса включает в себя понимание разницы между наличием законной страницы-назначения и страницы, которая позволяет посетителям фильтровать результаты.
И убедитесь в том, чтобы обрабатывать их соответственно при разработке URL.
URL страницы-назначения (и канонической) должны выглядеть так:
site.com/shirts/long-sleeve/site.com/shirts/v-neck/site.com/shirts/collared/
А URL отфильтрованных результатов может выглядеть примерно так:
site.com/shirts/long-sleeve/?size=small&color=red&display=12&sort=pricesite.com/shirts/v-neck/?color=redsite.com/shirts/collared/?size=small&display=12&sort=price&color=red
Правильно построив свои URL, вы можете сделать две вещи:
- Добавьте правильный канонический тег (все перед «?» в URL).
- Зайдите в Google Search Console и скажите Google игнорировать все такие параметры.
Если вы последовательно используете параметры только для фильтрации и сортировки контента, вам не придется беспокоиться о том, что случайно говорите Google не индексировать ценный параметр… потому что ни один из них не является таковым.
Но поскольку тег канонического адреса является всего лишь сигналом, вы должны выполнить второй шаг для лучших результатов. И помните, что это касается только Google. Вы должны сделать то же самое с Bing.
Профессиональный совет разработчика: Поисковые системы обычно игнорируют все справа от символа «#» в URL.
Если вы программируете это в каждый URL перед любым параметром, вам не придется беспокоиться о том, что канонический адрес будет всего лишь временным решением:
site.com/shirts/long-sleeve/#?size=small&color=red&display=12&sort=pricesite.com/shirts/v-neck/#?color=redsite.com/shirts/collared/#?size=small&display=12&sort=price&color=red
Если любая поисковая система получит доступ к указанным URL, она будет индексировать только каноническую часть URL и игнорировать остальное.
Проблема: Дублирование страниц посадочных страниц и тестирования A/B
Не редкость, когда маркетологи создают множество версий похожего контента, будь то посадочная страница для рекламы или для целей A/B-тестирования.
Это может принести вам отличные данные и обратную связь, но если эти страницы открыты для индексации поисковыми системами, это может вызвать проблемы с дублированием контента.
Решение: NoIndex
Вместо использования канонического тега для указания на основную страницу, лучшее решение заключается в добавлении мета-тега noindex на каждую страницу, чтобы полностью исключить их из индекса поисковых систем.
Обычно эти страницы склонны быть "сиротами", не имея прямых ссылок на них изнутри сайта. Однако это не всегда удерживает поисковые системы от их обнаружения.
Канонический тег предназначен для передачи ценности и авторитета страницы основной странице, но поскольку эти страницы не должны собирать какую-либо ценность, их полное исключение из индекса является предпочтительным.
Когда дублирование контента не (очень) проблематично
Одним из наиболее распространенных мифов SEO является существование штрафа за дублированный контент. Его нет. По крайней мере, не больше, чем за то, что вы получите штраф за то, что не заправляете свою машину и пускаете ее на пустом ходу.
Google может не активно штрафовать за дублированный контент, но это не означает, что из-за этого не происходят естественные последствия. Без угрозы штрафа маркетологам предоставляется больше гибкости в выборе того, с какими последствиями они готовы смириться.
Хотя я бы посоветовал настойчиво устранить (а не просто "приклеить пластырем") весь дублированный контент на сайте, дублирование вне сайта может создавать большую ценность по сравнению с последствиями.
Получение ценного контента для публикации вне сайта может помочь вам создать узнаваемость бренда таким образом, который невозможен при его публикации на собственном сайте. Это связано с тем, что у многих издателей вне сайта есть более широкая аудитория и гораздо больший охват в социальных сетях.
Ваш контент, опубликованный на вашем собственном сайте, может достичь тысяч взглядов, но, опубликованный вне сайта, он может достичь сотен тысяч.
Многие издатели обычно ожидают сохранения эксклюзивных прав на публикуемый контент, но некоторые позволяют вам использовать его повторно на вашем собственном сайте после короткого периода ожидания. Это позволяет вам получить дополнительную экспозицию и, в то же время, иметь возможность наращивать свою собственную аудиторию, публикуя контент на своем сайте в более поздний период.
Однако этот вид распределения статей должен быть ограничен, чтобы быть эффективным для всех. Если вы распространяете свой контент по сотням других сайтов для повторной публикации, стоимость этого контента резко уменьшается.
И, как правило, это мало что делает для укрепления вашего бренда, потому что сайты, готовые публиковать массово дублированный контент, изначально не имеют большой ценности. В любом случае, взвесьте плюсы и минусы публикации вашего контента в нескольких местах.
Если дублирование с большим брендингом перевешивает более низкую стоимость авторитета, который вы бы получили с уникальным контентом на своем собственном сайте, тогда, конечно же, следуйте измеренной стратегии повторной публикации.
Но ключевое слово здесь – измеренной.
Тем, чего вы не хотите, является тем сайтом, на котором есть только дублированный контент. На этом этапе вы начинаете подрывать ценность, которую вы пытаетесь создать для своего бренда. Понимая проблемы, решения и, в некоторых случаях, ценность дублированного контента, вы можете начать процесс устранения того дублирования, которое вам не нужно, и преследовать тот, которое вам нужно. В конце концов, вы хотите создать сайт, который известен своим крепким, уникальным контентом, и использовать этот контент для получения максимальной возможной ценности.