
автор: Anna Crowe
Изучение того, как настроить файл robots.txt и мета-теги robots, является важным элементом успеха в техническом SEO. Это краткое руководство поможет вам правильно их реализовать.
Может быть, это только у меня, или слова "мета-теги robots" и "robots.txt" звучат как что-то, что сказал бы Шварценеггер в "Терминаторе 2"?
Именно поэтому я начал заниматься SEO – казалось, будущее, но в то время чрезмерно техническое для моих навыков.
Надеюсь, это руководство сделает настройку мета-тегов robots и файлов robots.txt менее вызывающей тошноту. Давайте начнем.
Meta Robots Tags против Robots.txt
Прежде чем мы погрузимся в основы того, что такое мета-теги robots и файлы robots.txt, важно знать, что нет одной стороны, которая лучше использовать в SEO.
Файлы robots.txt указывают краулерам, что следует краулить по всему сайту.
В то время как мета-теги robots углубляются в детали конкретной страницы.
Я предпочитаю использовать мета-теги robots для многих вещей, которые другие специалисты SEO могут считать слишком сложными в файле robots.txt.
Нет правильного или неправильного ответа. Это личное предпочтение на основе вашего опыта.
Что такое Robots.txt?
Файл robots.txt сообщает краулерам, что следует краулить.
Это часть протокола исключения краулеров (REP).
Googlebot – пример краулера.
Google разворачивает Googlebot для обхода веб-сайтов и записи информации о сайте для понимания того, как ранжировать сайт в результатах поиска Google.
Вы можете найти файл robots.txt любого сайта, добавив /robots.txt после веб-адреса, например, так:
www.mywebsite.com/robots.txt
Вот как выглядит базовый, свежий файл robots.txt:
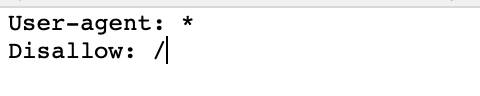
Звездочка * после user-agent говорит краулерам, что файл robots.txt предназначен для всех ботов, посещающих сайт.
Косая черта / после "Disallow" говорит роботу не переходить на любые страницы сайта.
Вот пример файла robots.txt от Moz.

Вы видите, что они сообщают краулерам, какие страницы краулить, используя user-agents и директивы. Я расскажу о них чуть позже.
Почему важен файл Robots.txt?
Я не могу сказать, сколько клиентов обращаются ко мне после миграции сайта или запуска нового сайта и спрашивают меня: Почему мой сайт не ранжируется после месяцев работы?
Я бы сказал, что 60% причина в том, что файл robots.txt не был правильно обновлен.
Это означает, что ваш файл robots.txt по-прежнему выглядит так:
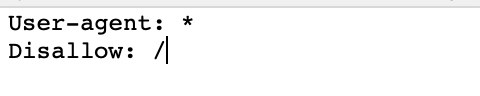
Это блокирует все веб-краулеры, посещающие ваш сайт.
Еще одна причина, по которой файл robots.txt важен, заключается в том, что у Google есть такая штука, как бюджет краула.
Google говорит:
«Googlebot разработан так, чтобы быть хорошим гражданином веба. Краулинг – его главный приоритет, при этом он обеспечивает нормальное взаимодействие с пользователями, посещающими сайт. Мы называем это «лимитом скорости краула», который ограничивает максимальную скорость получения данных для данного сайта.
Проще говоря, это представляет собой количество одновременных параллельных соединений, которые Googlebot может использовать для краулинга сайта, а также время ожидания между получениями данных».
Так что, если у вас большой сайт с низкокачественными страницами, которые вы не хотите, чтобы Google краулил, вы можете сказать Google «Запретить» их в вашем файле robots.txt.
Это освободит ваш бюджет краула, чтобы он краулил только высококачественные страницы, которые вы хотите, чтобы Google ранжировал для вас.
На данный момент нет четких и строгих правил для файлов robots.txt... пока.
Google объявил в июле 2019 года о предложении начать внедрение определенных стандартов, но пока что я придерживаюсь лучших практик, которые использовала в течение последних нескольких лет.
Основы Robots.txt
Как использовать Robots.txt
Использование robots.txt крайне важно для успешного SEO.
Однако непонимание его работы может заставить вас почесать затылок, пытаясь понять, почему вы не ранжируетесь.
Поисковые системы будут краулить и индексировать ваш сайт на основе того, что вы сообщите им в файле robots.txt с использованием директив и выражений.
Ниже приведены распространенные директивы robots.txt, которые вам следует знать:
- User-agent: * — Это первая строка в вашем файле robots.txt, чтобы объяснить краулерам правила того, что вы хотите, чтобы они краулили на вашем сайте. Звездочка информирует всех пауков.
- User-agent: Googlebot — Это говорит только о том, что вы хотите, чтобы краулер Google краулил.
- Disallow: / — Это говорит всем краулерам не краулировать ваш весь сайт.
- Disallow: — Это говорит всем краулерам краулировать ваш весь сайт.
- Disallow: /staging/ — Это говорит всем краулерам игнорировать ваш тестовый сайт.
- Disallow: /ebooks/* .pdf — Это говорит краулерам игнорировать все ваши форматы PDF, которые могут вызывать проблемы с дублированием контента.
User-agent: Googlebot
Disallow: /images/ — Это говорит только краулеру Googlebot игнорировать все изображения на вашем сайте.
* — Это рассматривается как шаблон, представляющий любую последовательность символов.
$ — Используется для сопоставления конца URL.
Для создания файла robots.txt я использую Yoast для WordPress. Он уже интегрируется с другими функциями SEO на моих сайтах.
Но прежде чем вы начнете создавать свой файл robots.txt, вот несколько основных моментов, которые стоит помнить:
Правильно форматируйте свой файл robots.txt. SEMrush приводит отличный пример того, как должен быть правильно отформатирован файл robots.txt. Вы видите, что структура следует следующему порядку: User-agent → Disallow → Allow → Host → Sitemap. Это позволяет паукам поисковых систем получать доступ к категориям и веб-страницам в правильном порядке.

Убедитесь, что каждый URL, который вы хотите "Allow:" или "Disallow:", размещен на отдельной строке, как это делает Best Buy ниже. И не разделяйте пробелами.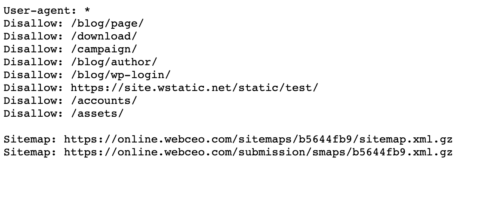
Всегда используйте строчные буквы для названия вашего файла robots.txt, как это делает WebCEO.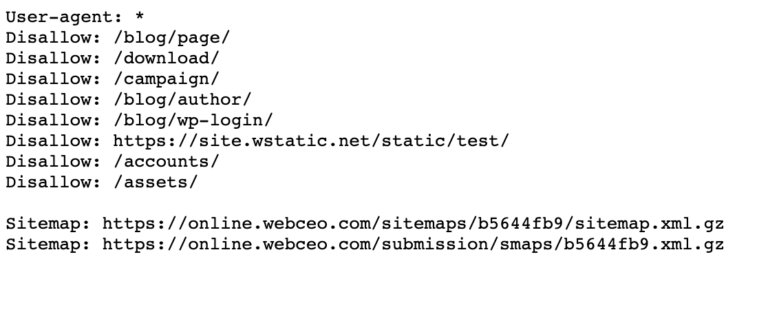
- Не используйте никакие специальные символы, кроме * и $. Другие символы не распознаются.
- Создавайте отдельные файлы robots.txt для разных поддоменов. Например, "hubspot.com" и "blog.hubspot.com" имеют индивидуальные файлы и оба имеют разные файлы robots.txt.
- Используйте # для комментариев в вашем файле robots.txt. Краулеры не уважают строки с символом #.
- Если страница запрещена в файлах robots.txt, равновесие ссылок не передается.
- Никогда не используйте robots.txt для защиты или блокировки конфиденциальных данных.
Что скрывать с помощью Robots.txt
Файлы robots.txt часто используются для исключения определенных каталогов, категорий или страниц из SERP.
Вы можете исключить, используя директиву "disallow".
Вот несколько обычных страниц, которые я скрываю с использованием файла robots.txt:
- Страницы с дублирующимся контентом (часто контент для печати)
- Страницы пагинации
- Динамические страницы продуктов и услуг
- Страницы учетной записи
- Страницы администратора
- Корзина для покупок
- Чаты
- Страницы благодарности
Это особенно полезно для электронной коммерции с использованием параметров, как это делает Macy's.

И вы можете видеть здесь, как я запретил страницу благодарности.
Важно знать, что не все краулеры будут следовать вашему файлу robots.txt.
Плохие боты могут полностью игнорировать ваш файл robots.txt, поэтому убедитесь, что на заблокированных страницах нет конфиденциальных данных.
Общие ошибки в файле robots.txt
После управления файлами robots.txt более 10 лет я вижу несколько общих ошибок:
Ошибка №1: Верхний регистр в имени файла
Возможное имя файла — robots.txt, а не Robots.txt или ROBOTS.TXT.
Следуйте строчным буквам, всегда, когда речь идет о SEO.
Ошибка №2: Не помещение файла robots.txt в главный каталог
Если вы хотите, чтобы ваш файл robots.txt был найден, вы должны поместить его в главный каталог вашего сайта.
Неправильно
www.mysite.com/tshirts/robots.txt
Правильно
www.mysite.com/robots.txt
Ошибка №3: Неправильно отформатированный User-Agent
Неправильно
Disallow: Googlebot
Правильно
User-agent: Googlebot
Disallow: /
Ошибка №4: Упоминание нескольких каталогов в одной строке 'Disallow'
Неправильно
Disallow: /css/ /cgi-bin/ /images/
Правильно
Disallow: /css/
Disallow: /cgi-bin/
Disallow: /images/
Ошибка №5: Пустая строка в 'User-Agent'
Неправильно
User-agent:
Disallow:
Правильно
User-agent: *
Disallow:
Ошибка №6: Зеркальные веб-сайты и URL-адреса в директиве Host
Будьте внимательны при упоминании директив 'host', чтобы поисковые системы правильно вас понимали:
Неправильно
User-agent: Googlebot
Disallow: /cgi-bin
Правильно
User-agent: Googlebot
Disallow: /cgi-bin
Host: www.site.com
Если ваш сайт имеет https, правильный вариант:
User-agent: Googlebot
Disallow: /cgi-bin
Host: https://www.site.com
Ошибка №7: Перечисление всех файлов внутри каталога
Неправильно
User-agent: *
Disallow: /pajamas/flannel.html
Disallow: /pajamas/corduroy.html
Disallow: /pajamas/cashmere.html
Правильно
User-agent: *
Disallow: /pajamas/
Disallow: /shirts/
Ошибка №8: Отсутствие инструкций Disallow
Инструкции Disallow необходимы, чтобы поисковые боты понимали вашу цель.
Неправильно
User-agent: Googlebot
Host: www.mysite.com
Правильно
User-agent: Googlebot
Disallow:
Host: www.mysite.com
Ошибка №9: Блокировка всего сайта
Неправильно
User-agent: Googlebot
Disallow: /
Правильно
User-agent: Googlebot
Disallow:
Ошибка №10: Использование различных директив в разделе *
Неправильно
User-agent: *
Disallow: /css/
Host: www.example.com
Правильно
User-agent: *
Disallow: /css/
Ошибка №11: Неверный HTTP-заголовок
Неправильно
Content-Type: text/html
Правильно
Content-Type: text/plain
Ошибка №12: Отсутствие Sitemap
Всегда размещайте свои карты сайта внизу вашего файла robots.txt.
Неправильно

Правильно

Ошибка №13: Использование noindex
Google объявил в 2019 году, что больше не будет учитывать директиву noindex, используемую в файлах robots.txt.
Так что вместо этого используйте мета-теги robots, о которых я расскажу ниже.
Неправильно
noindex thank you robots
Правильно
robots thank you
Ошибка №14: Запрещение страницы в файле robots.txt, но при этом создание ссылок на нее
Если вы запретили страницу в файле robots.txt, Google все равно будет индексировать эту страницу, если у вас есть внутренние ссылки на нее.
Вам нужно удалить эти ссылки, чтобы пауки полностью прекратили индексацию этой страницы.
Если вы когда-либо сомневаетесь, вы можете проверить, какие страницы индексируются, в отчете о покрытии Google Search Console.
Вы должны увидеть что-то вроде этого:
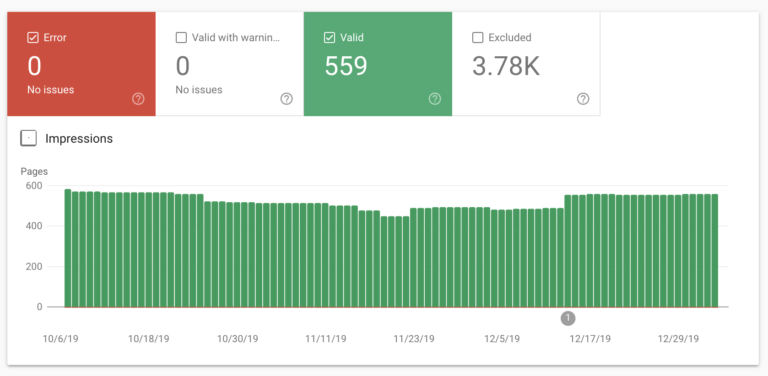
А также вы можете использовать инструмент проверки robots.txt от Google.
Однако, если вы используете инструмент проверки наличия мобильной версии от Google, он не будет следовать вашим правилам в файле robots.txt.
Мета-теги Robots (также называемые директивами мета-тегов robots) – это фрагменты HTML-кода, которые сообщают поисковым роботам, как индексировать страницы на вашем веб-сайте.
Что такое мета-теги robots?
Мета-теги robots добавляются в раздел <head> веб-страницы. Вот пример:
<meta name="robots" content="noindex" />
Мета-теги robots состоят из двух частей.
Первая часть тега – name='''.
Здесь вы идентифицируете user-agent. Например, "Googlebot".
Вторая часть тега – content=''.
Здесь вы сообщаете ботам, что вы хотите, чтобы они делали.
Типы мета-тегов robots
Мета-теги robots имеют два типа тегов:
- Мета-тег robots.
- X-robots-tag.
Тип 1: Мета-тег Robots
Мета-теги robots часто используются маркетологами SEO. Он позволяет вам сообщать user-agent'ам (думайте о Googlebot) об индексации конкретных областей. Вот пример:
<meta name="googlebot" content="noindex, nofollow">
Этот мета-тег robots говорит краулеру Google, Googlebot, не индексировать страницу в поисковых системах и не следовать по обратным ссылкам. Таким образом, эта страница не будет частью SERPs. Я бы использовал этот мета-тег robots для страницы благодарности после загрузки электронной книги.
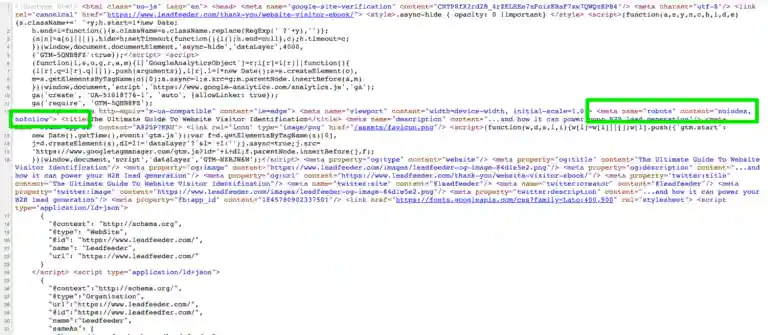
Теперь, если вы посмотрите на код страницы, вы увидите, что там указаны noindex и nofollow.
Если вы используете различные директивы мета-тегов Robots для различных пользовательских агентов поиска, вам придется использовать отдельные теги для каждого бота.
Крайне важно не размещать мета-теги Robots за пределами раздела <head>.
Тип 2: X-robots-tag
x-robots-tag позволяет делать то же самое, что и мета-теги robots, но в заголовках HTTP-ответа. По сути, это предоставляет больше функциональности, чем мета-теги robots. Однако для этого вам понадобится доступ к файлам .php, .htaccess или сервера.
Например, если вы хотите заблокировать изображение или видео, но не всю страницу, вы бы использовали x-robots-tag вместо этого.
Параметры мета-тегов robots
Есть много способов использования директив мета-тегов robots в коде. Но сначала вам нужно понять, что это за директивы и что они делают. Вот разбор директив мета-тегов robots:
- all – Нет ограничений для индексации и содержимого. Эта директива используется по умолчанию. Она не влияет на работу поисковых систем. Я использовал ее как ярлык для index, follow.
- index – Позволяет поисковым системам индексировать эту страницу в их результатах поиска. Это значение по умолчанию. Вам не нужно добавлять его на свои страницы.
- noindex – Удаляет страницу из индекса и результатов поиска. Это означает, что пользователи не найдут ваш сайт или перейдут по ссылке.
- follow – Позволяет поисковым системам следовать за внутренними и внешними обратными ссылками на этой странице.
- nofollow – Не разрешать следовать за внутренними и внешними обратными ссылками. Это означает, что эти ссылки не передадут вес ссылок.
- none – То же, что и мета-теги noindex и nofollow.
- noarchive – Не показывать ссылку "Сохраненная копия" в SERPs.
- nosnippet – Не показывать расширенную версию описания этой страницы в SERPs.
- notranslate – Не предлагать перевод этой страницы в SERPs.
- noimageindex – Не индексировать изображения на странице.
- unavailable_after: [RFC-850 date/time] – Не показывать эту страницу в SERPs после указанной даты/времени. Используйте формат RFC 850.
- max-snippet – Устанавливает максимальное количество символов в мета-описании.
- max-video-preview – Устанавливает количество секунд, в течение которых будет предварительный просмотр видео.
- max-image-preview – Устанавливает максимальный размер предварительного просмотра изображения.
Иногда разные поисковые системы принимают разные параметры мета-тегов. Вот их разбивка:
| Value | Bing | Yandex | |
| index | Yes | Yes | Yes |
| noindex | Yes | Yes | Yes |
| none | Yes | Doubt | Yes |
| noimageindex | Yes | No | No |
| follow | Yes | Doubt | Yes |
| nofollow | Yes | Yes | Yes |
| noarchive | Yes | Yes | Yes |
| nosnippet | Yes | No | No |
| notranslate | Yes | No | No |
| unavailable_after | Yes | No | No |
Как использовать мета-теги Robots
Если у вас есть веб-сайт на WordPress, у вас есть множество вариантов плагинов для настройки ваших мета-тегов Robots. Я предпочитаю использовать Yoast. Это всё-в-одном плагин SEO для WordPress, предоставляющий множество функций. Тем не менее, существуют также плагины Meta Tags Manager и GA Meta Tags.
Для пользователей Joomla я рекомендую EFSEO и Tag Meta.
Вне зависимости от того, на чем построен ваш сайт, вот три совета по использованию мета-тегов Robots:
- Сохраняйте регистр. Поисковые системы распознают атрибуты, значения и параметры как в верхнем, так и в нижнем регистре. Я рекомендую придерживаться нижнего регистра для улучшения читаемости кода. Кроме того, если вы SEO-специалист, лучше приучить себя использовать нижний регистр.
- Избегайте множественных тегов <meta>. Использование нескольких мета-тегов вызовет конфликты в коде. Используйте несколько значений в вашем теге <meta>, например, так: <meta name="robots" content="noindex, nofollow">.
- Не используйте противоречащие мета-теги, чтобы избежать ошибок индексации. Например, если у вас есть несколько строк кода с мета-тегами, такими как <meta name="robots" content="follow"> и <meta name="robots" content="nofollow">, будет учтено только "nofollow". Это происходит потому, что роботы первыми применяют ограничительные значения.
Файл Robots.txt и Мета-теги Robots работают вместе
Одна из самых распространенных ошибок, которую я вижу при работе с веб-сайтами своих клиентов, – это несоответствие файла robots.txt тому, что указано в мета-тегах Robots.
Например, файл robots.txt скрывает страницу от индексации, но мета-теги Robots делают обратное.
Помните пример от Leadfeeder, который я показала выше?
Таким образом, вы заметите, что эта страница благодарности запрещена в файле robots.txt и использует мета-теги Robots noindex, nofollow.
По моему опыту, Google придает приоритет тому, что запрещено в файле robots.txt.
Однако вы можете избежать несоответствия мета-тегов Robots и robots.txt, четко сообщив поисковым системам, какие страницы следует индексировать, а какие нет.
Заключение
Если вы все еще вспоминаете дни, когда покупка фильма в Blockbuster в торговом центре казалась актуальной, то использование robots.txt или мета-тегов может показаться вам сложным.
Но если вы уже насладились просмотром "Странных вещей", добро пожаловать в будущее.
Надеюсь, этот руководство предоставило вам больше информации о основах robots.txt и мета-тегов. Если после прочтения этого поста вы надеялись на роботов на реактивных ранцах и путешествие во времени, мне жаль.